시놀로지 NAS에 AI 모델을 설치한다고 하면 왠지 어렵게 느껴지는데, 실제로 해보면 생각보다 단계가 단순합니다. Container Manager에서 Ollama 이미지를 받고, 모델을 pull하고, Open WebUI를 연결하면 끝이거든요.
다만 막히는 지점이 꽤 명확합니다. 포트 설정을 빼먹거나, 볼륨 경로를 잘못 잡거나, 메모리 제한이 걸려 있거나. 이 글에서는 DSM 7.2 이상 + Container Manager 환경 기준으로 Gemma 4를 처음 설치하는 전 과정을 순서대로 정리합니다. 설치 전 확인해야 할 기종·RAM 조건이 궁금하다면 시놀로지 NAS 로컬 AI 실행 조건 글을 먼저 보고 오시는 걸 추천드립니다.
설치를 시작하기 전에 아래 세 가지를 먼저 체크하세요. 하나라도 빠지면 중간에 막히는 경우가 많습니다.
설치는 크게 세 단계입니다. 순서를 지키는 게 중요해요. Open WebUI를 먼저 깔면 Ollama와 연결이 안 되는 경우가 있거든요.
간단하게 말하면요. Ollama가 AI 모델을 실행하는 엔진이고, Open WebUI가 브라우저에서 ChatGPT처럼 대화할 수 있게 해주는 인터페이스입니다. 둘을 따로 설치하고 연결하는 구조예요.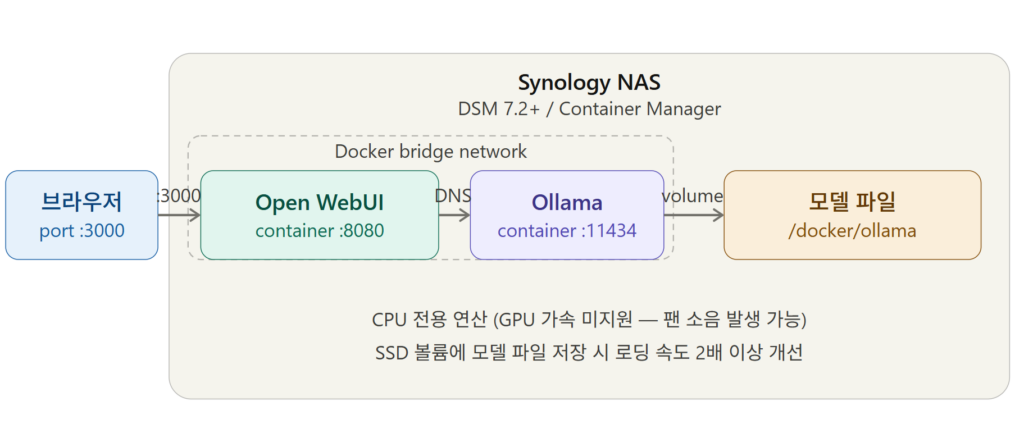
Container Manager를 열고 왼쪽 메뉴에서 레지스트리를 클릭합니다. 검색창에 ollama를 입력하면 ollama/ollama 이미지가 나옵니다. 선택 후 다운로드 버튼을 누르고, 태그는 latest로 선택하면 됩니다.
다운로드가 완료되면 왼쪽 메뉴 이미지 탭에서 확인할 수 있어요.
이미지 탭에서 ollama/ollama를 선택하고 실행을 클릭합니다. 컨테이너 생성 화면에서 아래 항목을 반드시 설정해야 합니다.
표에서 가장 중요한 건 볼륨 마운트와 메모리 제한입니다. 볼륨을 설정하지 않으면 컨테이너를 재시작할 때마다 다운로드한 모델이 전부 날아가요. 메모리 제한은 기본값이 걸려 있는 경우가 있으니 반드시 확인하는 게 좋습니다.
볼륨으로 지정할 NAS 폴더 /docker/ollama는 미리 File Station에서 생성해두는 게 좋습니다. 폴더가 없으면 볼륨 마운트가 작동하지 않는 경우가 있거든요.
폴더 권한 오류가 나는 경우
/docker/ollama
폴더를 생성했는데 모델 다운로드 중 "permission denied" 오류가 뜨면 권한 문제일 가능성이 높습니다. File Station에서 해당 폴더를 우클릭 → 속성 → 권한 탭에서 Everyone 또는 docker 그룹에 읽기·쓰기 권한이 설정돼 있는지 확인하세요.(혹은 sc-download 그룹이나 현재 로그인한 사용자 그룹에 권한을 주면 더 안전합니다) 이 설정이 빠지면 컨테이너 내부에서 폴더에 쓰기가 안 됩니다.
설정 완료 후 컨테이너를 실행합니다. Container Manager 컨테이너 탭에서 ollama가 실행 중 상태인지 확인하세요. 로그 탭을 열어보면 Listening on 0.0.0.0:11434 문구가 보이면 정상입니다.
Container Manager에서 실행 중인 ollama 컨테이너를 클릭하고, 상단 터미널 탭을 선택합니다. 새 터미널 열기를 클릭하면 컨테이너 내부 쉘이 열립니다. SSH 설정 없이도 바로 접속할 수 있는 방법이라 처음에는 이 방법이 더 편합니다.
pull 명령어를 입력하기 전에 내 RAM에 맞는 모델 크기를 먼저 정하는 게 순서입니다. 다운로드 후 RAM이 부족해서 못 쓰는 상황이 꽤 자주 나오거든요.
Gemma 4 E4B(Effective 4B)는 구글이 NAS처럼 GPU 없는 로컬 환경을 겨냥해 효율성을 집중 개선한 모델입니다. 파라미터 수는 적지만 한국어 명령 이행 능력과 추론 품질이 7B급과 비교해도 크게 뒤처지지 않아요. 12GB 구성에서 속도와 품질을 동시에 잡을 수 있는 현실적인 최선입니다. 시놀로지 환경에서 처음 시작한다면 다른 모델을 고민하기 전에 이걸 먼저 써보는 걸 권장합니다.
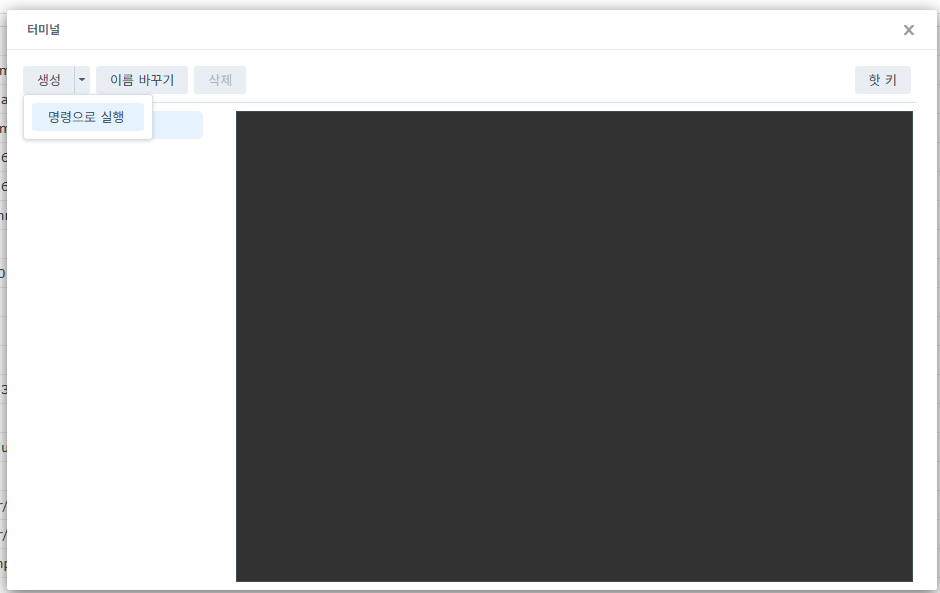
컨테이너 터미널을 실행한 화면에서 좌측 상단에 [생성] 버튼을 누르고 '명령으로 실행'을 클릭합니다. (드롭다운 메뉴에 bash가 있으면 bash를 선택하시면 됩니다.)
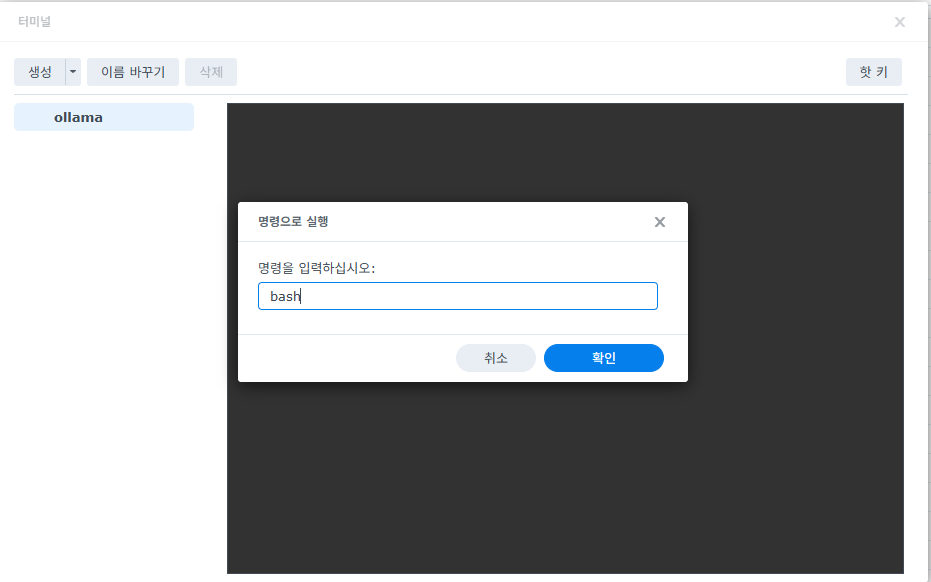
'명령을 입력하십시오:' 빈칸에 영어 소문자로 bash라고 입력하세요. 그러면 팝업창이 닫히면서 root@...:/# 같은 글씨가 나타납니다.
이제 터미널에서 내 RAM에 맞는 명령어를 입력합니다. 12GB 기준으로는 아래와 같습니다.
ollama pull gemma4:e4b다운로드가 시작되면 진행률이 표시됩니다. 파일 크기가 9GB 내외라 NAS 인터넷 연결 속도에 따라 10분~30분 정도 걸릴 수 있어요. 다운로드 중에는 터미널을 닫지 마세요.
완료 후 아래 명령어로 정상적으로 받아졌는지 확인할 수 있습니다.
ollama list목록에 gemma4:e4b가 보이면 성공입니다.
Ollama만 설치한 상태에서도 터미널로 AI를 쓸 수는 있어요. 그런데 실제로 편하게 쓰려면 브라우저에서 대화형으로 쓸 수 있는 Open WebUI를 붙이는 게 훨씬 낫습니다.
Container Manager → 레지스트리에서 open-webui를 검색합니다. ghcr.io/open-webui/open-webui 이미지를 선택하고 태그는 main으로 다운로드합니다.
환경 변수 OLLAMA_BASE_URL 설정이 핵심이에요. http://ollama:11434에서 ollama 부분이 앞서 만든 Ollama 컨테이너 이름과 정확히 일치해야 합니다. 이게 작동하는 이유는 Docker 내부 DNS 덕분이에요. 같은 bridge network 안의 컨테이너끼리는 IP 대신 컨테이너 이름을 주소처럼 쓸 수 있습니다. http://ollama:11434라고 쓰면 Docker가 알아서 Ollama 컨테이너의 내부 IP로 변환해줘요. 이름이 다르거나 네트워크가 분리돼 있으면 "Ollama에 연결할 수 없습니다" 오류가 뜨거든요.
연결이 안 된다면 http://NAS의내부IP:11434 형태로 직접 IP를 입력하는 방법으로 우회할 수 있어요. 이 경우에는 네트워크 설정과 무관하게 작동합니다.
단, 이 방식(컨테이너 이름으로 참조)이 작동하려면 두 컨테이너가 같은 Docker 네트워크에 있어야 합니다. Container Manager에서 네트워크를 따로 설정하지 않았다면 기본 bridge 네트워크를 공유하고 있어서 대부분 그냥 됩니다. 안 된다면 http://NAS의내부IP:11434 형태로 직접 IP를 입력하는 방법으로 우회할 수 있어요.
Open WebUI 컨테이너가 실행 중 상태가 되면 브라우저에서 아래 주소로 접속합니다.
http://NAS의내부IP:3000처음 접속하면 관리자 계정을 만드는 화면이 나옵니다.
처음 접속하면 관리자 계정을 만드는 화면이 나옵니다. 이 계정은 NAS 내부 데이터베이스에만 저장되므로 외부 서버에 가입하는 게 아니에요. 외부로 데이터가 전송되지 않으니 안심하고 만들면 됩니다. 이메일 형식으로 입력하면 되고, 실제로 이메일 인증이 필요한 건 아닙니다. 로그인 후 상단 모델 선택 드롭다운에서 gemma4:e4b가 보이면 연결 완료예요.
Container Manager UI에서 하나하나 설정하는 게 번거롭다면, YAML 파일을 붙여넣는 방식이 훨씬 빠릅니다. 오타나 설정 누락도 줄어들어요. Container Manager → 프로젝트 → 새 프로젝트 생성에서 아래 코드를 그대로 붙여넣으면 Ollama와 Open WebUI가 동시에 설치됩니다.
version: "3.8"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: always
ports:
- "11434:11434"
volumes:
- /volume1/docker/ollama:/root/.ollama
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: always
ports:
- "3000:8080"
environment:
- OLLAMA_BASE_URL=http://ollama:11434
volumes:
- /volume1/docker/open-webui:/app/backend/data
depends_on:
- ollama볼륨 경로 /volume1/docker/...는 내 NAS의 실제 볼륨 이름에 맞게 수정하세요. volume1이 아니라 volume2나 volume3일 수 있습니다. DSM → 저장소 관리자에서 확인할 수 있어요. SSD 전용 볼륨이 있다면 Ollama 경로를 해당 볼륨으로 지정하는 게 좋습니다.
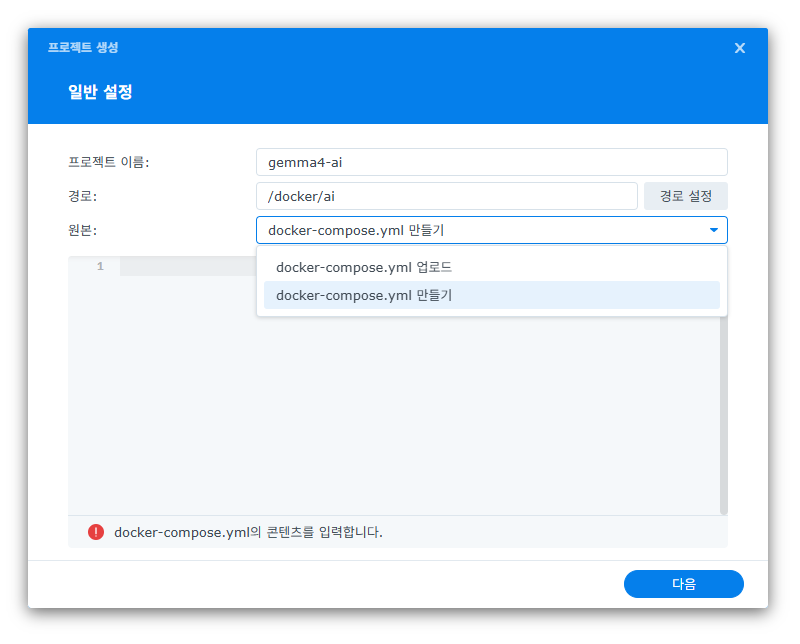
프로젝트 생성 화면에서 '원본'을 '업로드'가 아닌 'docker-compose.yml 생성'으로 선택하셔야 코드를 바로 붙여넣을 수 있는 창이 나옵니다. 코드를 붙여넣은 이후에 웹포털 설정 화면에서는 체크하지 말고 바로 '다음' 버튼을 누르셔서 완료하시면 됩니다. 수동으로 하나씩 설정하실 분들은 1~3단계를 차례로 따라오시고, YAML 코드를 쓰신 분들은 바로 2-3, 3-3단계(모델 다운로드)로 넘어가시면 됩니다.
depends_on 설정 덕분에 Ollama가 먼저 기동된 후 Open WebUI가 실행되는 순서도 자동으로 보장되고요. UI에서 수동 설정할 때 자주 생기는 네트워크 연결 오류가 줄어듭니다.설치는 됐는데 뭔가 이상한 경우, 대부분 아래 네 가지 중 하나입니다.
Error response from daemon: Head "https://registry-1.docker.io/... 에러가 뜨면서 다운로드가 안 되는 경우가 있습니다. 코드가 틀린 것이 아니라 NAS가 도커 허브 서버(다운로드 서버)를 찾지 못하는 DNS 네트워크 문제입니다.해결 방법:1.1.1.1(클라우드플레어) 또는 8.8.8.8(구글)을 입력하고 적용하세요. 다시 빌드해보면 정상적으로 다운로드가 시작됩니다.Gemma 4 e4b 기준으로 이런 작업들은 충분히 실용적인 속도가 나옵니다.
Gemma 4는 텍스트뿐 아니라 이미지 입력도 지원하는 멀티모달 모델입니다. 추가 설정 없이 Open WebUI에서 바로 쓸 수 있어요.
다만 이미지 분석은 텍스트보다 연산이 훨씬 많습니다. RAM 12GB 기준으로 고해상도 이미지 처리 시 응답 시간이 텍스트 대비 2~3배 걸릴 수 있어요. 저해상도 또는 리사이즈된 이미지로 먼저 테스트해보는 게 좋습니다.
클라우드 AI 구독료와 로컬 AI 운영 비용을 총액 기준으로 비교하면 실제로 언제 손익분기가 나는지 궁금하다면, 시놀로지 로컬 AI vs ChatGPT Plus 비용 비교 글을 보시길 추천드립니다. 참고로 ChatGPT 구독을 원화로 결제하느냐 달러로 결제하느냐에 따라 월 부담이 달라지기도 하는데, ChatGPT 원화·달러 결제 조건 비교 글을 참고해 보면 로컬 전환 결정에도 도움이 됩니다.
네, 이 가이드에서 설명한 Container Manager 터미널 방법을 쓰면 SSH 설정 없이도 모델 pull까지 전부 가능합니다. SSH가 익숙하다면 그쪽이 더 빠르지만, 필수는 아니에요.
컨테이너 재시작 정책을 "항상 재시작"으로 설정했다면 자동으로 실행됩니다. 다만 모델이 RAM에 올라오는 건 첫 대화 요청이 들어올 때라서, 재부팅 직후 첫 응답은 조금 더 걸릴 수 있어요.
저장 공간만 충분하면 여러 모델을 pull해서 보관할 수 있습니다. Open WebUI에서 모델을 선택해서 전환하는 방식으로 쓸 수 있어요. 다만 한 번에 두 모델을 동시에 올려두면 RAM을 두 배로 점유하니까, 사용하지 않는 모델은 꺼두는 게 좋습니다.
가능합니다. Ollama 컨테이너를 중지하고, /docker/ollama 폴더 자체를 새 위치로 복사한 뒤 볼륨 마운트 경로를 변경하면 됩니다. 다시 pull할 필요 없이 기존 모델 파일을 그대로 쓸 수 있어요.
Container Manager 레지스트리에서 ollama/ollama:latest를 다시 다운로드하고 기존 컨테이너를 새 이미지로 재생성하면 됩니다. 볼륨 마운트 경로를 그대로 유지하면 모델 파일은 업데이트 후에도 보존됩니다.
Open WebUI 자체에 Google 서비스 직접 연동 기능은 없습니다. 다만 내용을 복사해서 붙여넣는 방식으로 활용하는 건 충분히 가능해요. Google 저장공간 관리가 따로 필요하다면 Gmail 저장공간 정리 순서를 참고해두면 클라우드와 로컬 AI를 병행하는 환경 정리에 도움이 됩니다.
설치 자체보다 어떤 모델 크기를 선택하는지, 볼륨 경로를 SSD로 잡는지, 메모리 제한을 해제했는지가 실사용 만족도에 더 크게 영향을 줍니다. 이 세 가지만 잡아도 설치 후 "왜 이렇게 느리지?"라는 상황은 대부분 피할 수 있어요.
설치를 마치셨나요? 이제 로컬 AI 실전 활용법 5가지 글에서 개인정보 걱정 없이 로컬 AI를 비서로 부려먹는 방법을 확인해 보세요.
시놀로지 NAS 로컬 AI 실행 조건 전체 비교 바로 가기




