시놀로지 NAS에서 Ollama Cloud Gemma 4 31B로 로컬 AI 성능 한계 없애는 방법
맥북 M4 Pro에서도 Gemma 4 4B를 연속으로 돌리면 버벅이고 발열이 심해진다고 하죠? 시놀로지 NAS에서는 더더욱 한계를 느낄 수 밖에 없습니다.
그런데 최근 Ollama가 조용히 중요한 업데이트를 했습니다. Gemma 4 31B를 클라우드에서 무료로 쓸 수 있도록 한 것입니다. 하드웨어 한계 없이, 추가 비용 없이, 기존 n8n 워크플로에서 모델명 하나만 바꿔서요.
이전 글에서 NAS 로컬 AI 한계를 Claude API로 넘는 방법을 다뤘는데, 이번엔 돈을 전혀 안 쓰는 방법이에요. 조건이 있긴 하지만, NAS 자동화 구조와 딱 맞아서 사실상 제약이 없는 것과 같습니다.
• Ollama Cloud 무료 티어로 Gemma 4 31B 사용 가능 — 로컬 1.5B 대비 성능 차이가 큼
• 무료 조건: 동시 요청 불가, 순차 방식만 가능 — NAS 배치 자동화 구조와 완벽하게 맞음
• n8n 기존 워크플로에서 모델명 하나만 바꾸면 연동 완료 — 추가 설치나 API 키 불필요
Ollama Cloud가 뭔지 — 로컬이랑 어떻게 다른가
기존 Ollama는 내 기기에 모델을 설치해서 로컬에서 돌리는 방식이에요. NAS에 설치한 Ollama도 같은 방식이라 RAM 한도에 묶입니다.
Ollama Cloud는 다릅니다. 모델이 Ollama 서버에서 돌아가요. 내 기기는 요청을 보내고 결과를 받아오는 역할만 해요. 덕분에 NAS RAM이 아무리 적어도 31B 모델을 쓸 수 있습니다.
구조적으로는 Claude API나 OpenAI API랑 비슷한데, 결정적인 차이가 있어요. Gemma 4 31B는 Google DeepMind가 오픈소스로 공개한 모델이라 무료로 제공됩니다.
로컬 Ollama vs Ollama Cloud vs Claude API — 어떤 조건에서 어떤 걸 쓰나
표에서 핵심은 Ollama Cloud의 "동시 요청 불가" 조건이에요. 언뜻 보면 제약처럼 보이는데, NAS 자동화 구조와 맞춰보면 얘기가 달라집니다.
왜 NAS 배치 자동화에 딱 맞는가
Ollama Cloud 무료 티어의 제약: "동시 요청 안 됨 — 순차로 하나씩만"
NAS n8n 배치 처리 방식: "새벽에 파일 하나씩 순서대로 처리"
이게 완벽하게 일치해요. 실제로도 동시 요청 때문에 Rate limit이 발생한 경우가 있었지만, 순차 방식으로 바꾸니 에러가 없었다는 사용자 경험도 확인됐습니다.
Ollama Cloud 무료 티어 조건 정리
✅ 동시 요청 없이 순차 방식 → Rate limit 없음
✅ 주간 토큰 약 4~5M — 뉴스 1,000건 분류 시 주간 7~8% 사용 수준
✅ 다른 모델도 Cloud로 사용 가능
✅ 속도 체감상 준수한 편
⚠️ 프롬프트 캐싱 미지원
⚠️ 모델별로 tool, thinking 모드 지원 여부가 다름
주간 4~5M 토큰이 얼마나 되는지 감이 안 올 수 있어요. 문서 요약 한 건에 약 1,500토큰이라면 주간 2,500~3,000건 처리가 가능합니다. 일반적인 개인 NAS 자동화 용도로는 한도가 남는 수준이에요.
gemma4:31b-cloud 사용 전 — ollama.com 계정 인증 필요
gemma4:31b-cloud는 ollama.com 계정 인증이 돼 있어야 사용할 수 있어요. 인증 없이 쓰면 401: unauthorized 오류가 발생합니다.
인증은 어렵지 않아요. Container Manager 터미널에서 명령어 하나면 됩니다.
① ollama.com 계정 먼저 만들기
ollama.com → Sign Up → 무료 계정 생성
② Container Manager 터미널 열기
Container Manager → 컨테이너 → Ollama 컨테이너 선택 → 터미널 탭 → + 생성
③ 로그인 명령어 실행
실행하면 터미널에 인증용 URL이 출력됩니다. 그 URL을 복사해서 브라우저에서 열고 ollama.com 계정으로 로그인하면 인증 완료예요.
④ 모델 등록
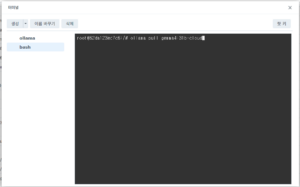
인증 후 같은 터미널에서 아래를 실행합니다.
완료되면 n8n, Open WebUI 등에서 모델 목록을 새로고침하면 gemma4:31b-cloud가 나타납니다.

컨테이너를 재시작해도 인증 상태가 유지돼요. NAS 볼륨에 인증 정보가 저장되기 때문입니다.
n8n 연동 방법 — 모델명 하나만 바꾸면 됩니다
이게 핵심이에요. 기존에 n8n에서 로컬 Ollama를 연동해뒀다면 HTTP Request 노드의 Body JSON에서 model 값만 바꾸면 됩니다. URL, 포트, 구조 전부 그대로예요.
"model": "qwen2.5:1.5b",
"prompt": "다음 내용을 3줄로 요약해줘:\n{{ $json.data }}",
"stream": false
}
"model": "gemma4:31b-cloud",
"prompt": "다음 내용을 3줄로 요약해줘:\n{{ $json.data }}",
"stream": false
}
gemma4:31b-cloud를 처음 요청하면 Ollama가 클라우드 모델을 인식하고 연결하는 시간이 잠깐 걸릴 수 있어요. 첫 응답 후부터는 정상 속도로 돌아옵니다. n8n에서 첫 실행 타임아웃이 발생하면 HTTP Request 노드의 Timeout 값을 60초 이상으로 늘려두세요.
URL은 그대로 http://[NAS-IP]:11434/api/generate를 씁니다. NAS의 로컬 Ollama가 31b-cloud 태그를 감지해서 자동으로 Ollama 클라우드로 라우팅해주는 구조예요.
n8n 설치가 아직 안 됐다면 시놀로지 NAS n8n 설치 + Ollama 연동 가이드에서 설치부터 기본 워크플로 구성까지 확인하세요.
주간 토큰 한도 내에서 어떤 자동화가 가능한가
주간 4~5M 토큰이 실제로 어떤 작업량인지 계산해봤습니다.
문서 요약 (입력 1,000토큰 + 출력 500토큰 = 건당 1,500토큰)
→ 주간 약 2,500~3,000건 처리 가능
파일 분류·태그 생성 (입력 500토큰 + 출력 100토큰 = 건당 600토큰)
→ 주간 약 6,000~8,000건 처리 가능
텔레그램 질문 답변 (입력 200토큰 + 출력 300토큰 = 건당 500토큰)
→ 주간 약 8,000~10,000건 처리 가능
개인 NAS 자동화 용도라면 한도 내에서 충분히 여유가 있습니다
로컬 AI가 필요한 경우 vs Ollama Cloud가 맞는 경우
로컬 Ollama 유지가 맞는 경우
의료 기록, 사내 문서처럼 외부 서버로 데이터가 나가면 안 되는 경우예요. 1.5B 품질이 아쉬워도 데이터 보안이 우선이라면 로컬이 맞습니다.
Ollama Cloud로 바꾸는 게 맞는 경우
민감하지 않은 문서 요약, 파일 분류, 텔레그램 봇 답변처럼 데이터 외부 전송이 괜찮은 경우예요. 무료로 31B 품질을 쓸 수 있어서 Claude API 비용 없이 대부분의 자동화가 커버됩니다.
Claude API가 여전히 맞는 경우
한국어 품질이 가장 중요하거나, 복잡한 분석·추론이 필요한 경우예요. Gemma 4 31B도 충분히 좋지만 Claude Sonnet 수준의 한국어 품질이 필요하다면 API가 맞습니다. 두 가지 비용 비교가 필요하다면 n8n + Claude API 연동 가이드에서 실제 비용 계산을 확인해보세요.
자주 묻는 질문
맞아요. 무료 티어 조건은 바뀔 수 있습니다. Google이 Gemma를 오픈소스로 공개한 건 변하지 않지만, Ollama Cloud의 무료 제공 조건은 회사 정책에 따라 달라질 수 있어요. 지금은 무료이지만, 유료로 전환되거나 한도가 줄어드는 경우를 대비해서 n8n 워크플로를 Claude API로 빠르게 전환할 수 있는 구조를 미리 만들어두는 게 좋습니다. 모델명 하나만 바꾸면 되니까 어렵지 않아요.
문서 요약, 파일 분류, 간단한 질문 답변에서는 실용적인 수준이에요. 실제로 뉴스 1,000건을 카테고리 분류한 사용 사례에서도 충분히 쓸 만하다는 평가가 있습니다. 다만 복잡한 맥락이 필요한 분석이나 긴 대화 흐름이 있는 경우에는 Claude에 비해 아쉬울 수 있어요.
가능합니다. n8n 워크플로에서 작업 종류에 따라 모델을 다르게 지정하면 돼요. 민감한 파일은 qwen2.5:1.5b로, 일반 문서는 gemma4:31b-cloud로 분기하는 구조를 n8n If 노드로 만들 수 있어요.
네, NAS의 로컬 Ollama가 클라우드 라우팅을 담당해요. Ollama가 설치돼 있고 실행 중인 상태에서 모델명을 gemma4:31b-cloud로 지정하면 자동으로 클라우드로 연결됩니다. Ollama 설치가 안 됐다면 시놀로지 NAS Ollama 설치 가이드를 먼저 보세요.
한도 초과 시 Rate limit 에러가 발생하고 요청이 거부돼요. n8n 워크플로에서 에러 핸들러를 추가해두면 한도 초과 시 로컬 모델로 자동 전환하거나 다음 주까지 처리를 멈추는 구조를 만들 수 있습니다. 일반적인 개인 자동화 용도라면 주간 한도를 초과하는 경우는 드뭅니다.
NAS 로컬 AI의 한계를 넘는 방법이 이제 두 가지가 됐어요. 비용이 부담스러우면 Ollama Cloud Gemma 31B, 한국어 품질이 최우선이면 Claude API. n8n 워크플로는 모델명 하나만 바꾸면 되니까 상황에 따라 전환도 쉽습니다.
NAS 로컬 AI 전체 활용 구조가 궁금하다면 시놀로지 NAS 로컬 AI 활용법 전체 정리에서 시리즈 흐름을 한눈에 볼 수 있어요.
이 글과 연결된 가이드
📌 시놀로지 NAS Ollama 설치 가이드
Ollama Cloud 연동 전 로컬 Ollama 설치 방법
📌 시놀로지 NAS n8n 설치 + Ollama 연동 자동화 가이드
n8n 워크플로 기본 구성 방법
📌 로컬 AI 한계를 Claude API로 넘는 방법
Ollama Cloud 한도 초과 시 대안 — 실제 비용 계산 포함
📌 시놀로지 NAS 기종별 로컬 AI 모델 실행 조건
내 NAS RAM에서 어떤 로컬 모델이 가능한지 확인





